हालात
पश्चिम बंगाल की मतदाता सूचियां 'सार्वजनिक' तो हैं, लेकिन कई पर्दे डाल रखे हैं चुनाव आयोग ने
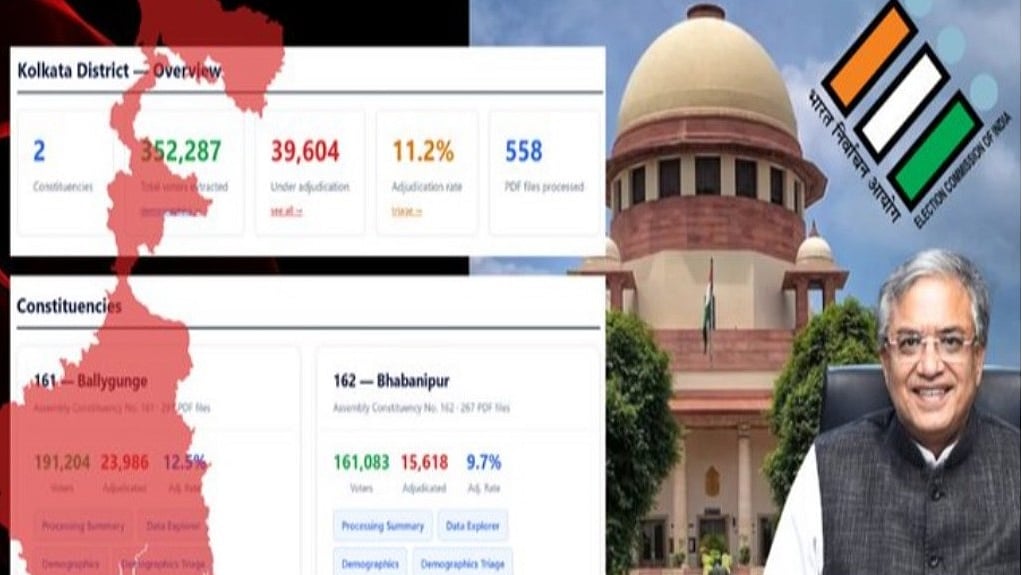
“पश्चिम बंगाल की 2026 की वोटर लिस्ट 'सार्वजनिक' हैं। लेकिन उन्हें पीडीएफ इमेज के रूप में प्रकाशित किया गया है। यह कोई संयोग नहीं है।” आल्टन्यूज ने शुक्रवार दो विधानसभा क्षेत्रों, भवानीपुर और बालीगंज पर अपनी जांच जारी करते हुए यह टिप्पणी की है।
“केंद्रीय चुनाव आयोग अपने एरोनेट (ERONET) सिस्टम के अंदर चुनावी डेटा को एक व्यवस्थित, मशीन-पठनीय फ़ॉर्मेट में रखता है। हालांकि, यह इस बात पर अंकुश लगाता है कि आम जनता को, शोधकर्ताओं को, और यहां तक कि राजनीतिक पार्टियों को भी सार्वजनिक रूप से क्या उपलब्ध कराया जाए। असल में, चिंता इस बात की नहीं है कि डेटा को व्यवस्थित किया जा सकता है या नहीं। यह पहले से ही व्यवस्थित है। चिंता इस बात की है कि उस फ़ॉर्मेट में इसका इस्तेमाल करने का अधिकार किसे मिलता है।” यह टिप्पणी ऑल्टन्यूज ने गुरुवार शाम को अपनी रिपोर्ट में की। इसके साथ ही भारत के चुनाव आयोग के कामकाज में पारदर्शिता की कमी को लेकर एक बार फिर सवाल खड़े हो गए हैं।
रिपोर्ट बताती है कि “…मतदाता सूचियों को खोजने लायक, मशीन-पठनीय फ़ाइलों के तौर पर अपलोड नहीं किया गया, बल्कि स्कैन की गई पीडीएफ इमेज के तौर पर अपलोड किया गया है; जो असल में छपे हुए पन्नों की तस्वीरें हैं। इन्हें खोजा नहीं जा सकता। इनका कोई सार्थक विश्लेषण नहीं किया जा सकता। हर पन्ना जान-बूझकर जांच-पड़ताल से बचने के लिए बनाया गया है; और राजनीतिक खींचतान के इस दौर में, यह एक अहम सवाल खड़ा करता है: जब सार्वजनिक डेटा को असल में इस्तेमाल के लायक ही न छोड़ा जाए, तो इसका फ़ायदा किसे होता है?” एक और शक, जिसे रिपोर्ट साफ़ तौर पर ज़ाहिर नहीं करती, वह यह है कि इस बात की क्या गारंटी है कि मशीन-पठनीय डेटा को चुनिंदा राजनीतिक पार्टियों और एजेंसियों—जैसे कि BJP—के साथ साझा नहीं किया जाएगा।
आल्टन्यूज की पूरी रिपोर्ट इस लिंक में देखी जा सकती है:
आल्टन्यूज ने घंटों की कड़ी मेहनत के बाद तमाम बैरियर को तोड़ा और पश्चिम बंगाल के दो निर्वाचन क्षेत्रों की मतदाता सूचियों का विश्लेषण किया। लेकिन इससे पहले उन्हें तीन खास मुश्किलों का सामना करना पड़ा:
पहली बाधा इस डेटा तक पहुंच की थी। अकेले भवानीपुर निर्वाचन क्षेत्र में ही 267 ज़ोन हैं। चुनाव आयोग की वेबसाइट से एक बार में केवल दस क्षेत्रों की जानकारी ही डाउनलोड की जा सकती है, और हर बार कैप्चा (CAPTCHA) डालना पड़ता है। इस वजह से ऑटोमेशन पूरी तरह से रुक गया। मैन्युअल रूप से डाउनलोड करने में घंटों लग गए।
दूसरी रुकावट फ़ॉर्मेट थी। स्कैन की गई पीडीएफ फ़ाइलें, औसतन, डिजिटल रूप से पढ़ी जा सकने वाली फ़ाइलों की तुलना में 228 गुना बड़ी होती हैं, फिर भी उनमें कोई भी अंदरूनी स्ट्रक्चर्ड डेटा नहीं होता। यह कोई तकनीकी कमी नहीं है। भारत आधार, यूपीआई और डिजिलॉकर जैसे सिस्टम बड़े पैमाने पर चलाता है। पीडीएफ के साथ-साथ एक सीएसवी (कॉमा से अलग किए गए मानों वाली एक कंप्यूटराइज़्ड फ़ाइल) पब्लिश करना, इसकी तुलना में बहुत ही आसान काम है। ऐसे फ़ॉर्मेट का न होना एक (जान-बूझकर लिया गया) फ़ैसला है।
तीसरी बाधा फ़ाइलों के भीतर ही मौजूद है। मोटे तौर पर, हर 10 वोटर एंट्री में से एक पर तिरछा “अंडर एडजुडिकेशन” (विचाराधीन) वॉटरमार्क लगा होता है, जो अक्सर नाम को ही ढक देता है। यह कोई इत्तेफ़ाक नहीं है। यह सीधे तौर पर ऑटोमेटेड डेटा निकालने में, और कुछ मामलों में तो मैन्युअल रूप से पढ़ने में भी बाधा डालता है।
रिपोर्ट में आगे कहा गया है, “हर परत जांच के एक अलग चरण को निशाना बनाती है: केप्चा डेटा इकट्ठा होने से रोकता है, इमेज फ़ॉर्मेट विश्लेषण को रोकता है, और वॉटरमार्क पहचान को रोकता है।” इसमें यह भी बताया गया है कि चुनाव आयोग के पास यह डेटा पहले से ही एक व्यवस्थित रूप में मौजूद है। ये पीडीएफ फ़ाइलें डेटाबेस से ही बनाई जाती हैं। इसलिए, मशीन-पठनीय फ़ाइलों के बिना, केवल स्कैन की गई इमेज प्रकाशित करना—जानकारी को नहीं, बल्कि उसके उपयोग को रोकने का एक जान-बूझकर लिया गया फ़ैसला है।
भारत के चुनाव आयोग ने एरोनेट (ERONET) बनाने में जनता का पैसा खर्च किया — यह एक सेंट्रलाइज़्ड सिस्टम है जिसने पश्चिम बंगाल में एक करोड़ से ज़्यादा "लॉजिकल गड़बड़ियों" (Logical Discrepancies) को फ़्लैग किया, लेकिन यह सार्वजनिक तौर पर बताने से मना कर दिया कि ये फ़्लैग कैसे आए। एक लोकतंत्र में, जो डेटा तकनीकी तौर पर सार्वजनिक होता है, वह व्यावहारिक तौर पर भी सुलभ होना चाहिए। रिपोर्ट में आगे कहा गया है, "जब ऐसा नहीं होता, तो रुकावट तकनीकी नहीं, बल्कि राजनीतिक होती है।"
यह रिपोर्ट चुनाव आयोग द्वारा अतीत में दिए गए उन कई तर्कों को याद दिलाती है, जिनके आधार पर उसने मतदाता सूचियों को केवल इमेज-आधारित फ़ॉर्मेट तक सीमित रखा था। “जनवरी 2018 में, उसने सभी राज्यों के मुख्य निर्वाचन अधिकारियों को निर्देश दिया था कि वे मतदाता सूचियों को इमेज फ़ाइलों के रूप में प्रकाशित करें; इसके पीछे उसने डेटा सुरक्षा संबंधी चिंताओं—विशेष रूप से विदेशी तत्वों द्वारा इसके दुरुपयोग के जोखिम—का हवाला दिया था।”
जब कांग्रेस नेता कमल नाथ ने अदालत में इस नीति को चुनौती दी, तो आयोग ने यह तर्क दिया कि खोजने योग्य और मशीन-पठनीय प्रारूपों से बड़े पैमाने पर डेटा माइनिंग संभव हो जाएगी, जिससे मतदाताओं की निजता का उल्लंघन होने की आशंका है। सुप्रीम कोर्ट ने इस दावे की मेरिट के आधार पर जांच करने से इनकार कर दिया, और प्रारूप के चयन का अधिकार आयोग के विवेक पर छोड़ दिया।
हाल ही में, अगस्त 2025 में मुख्य चुनाव आयुक्त ज्ञानेश कुमार ने दावा किया कि मशीन-पठनीय फ़ाइलें असल में "प्रतिबंधित" हैं, क्योंकि उन्हें "एडिट किया जा सकता है," जिससे उनके दुरुपयोग का रास्ता खुल जाता है। इस तर्क की व्यापक रूप से आलोचना की गई है, क्योंकि यह तकनीकी रूप से सही नहीं है। किसी डेटासेट की डाउनलोड की गई कॉपी को एडिट करने से, आयोग द्वारा रखे गए मूल रिकॉर्ड में कोई बदलाव नहीं होता है और न ही हो सकता है। आधिकारिक सूचियों की विश्वसनीयता इस बात पर निर्भर नहीं करती कि उन्हें सार्वजनिक रूप से किस फ़ॉर्मेट में साझा किया जाता है।
प्रिय पाठकों हमारे टेलीग्राम (Telegram) चैनल @navjivanindia से जुड़िए और पल-पल की ताज़ा खबरें पाइए